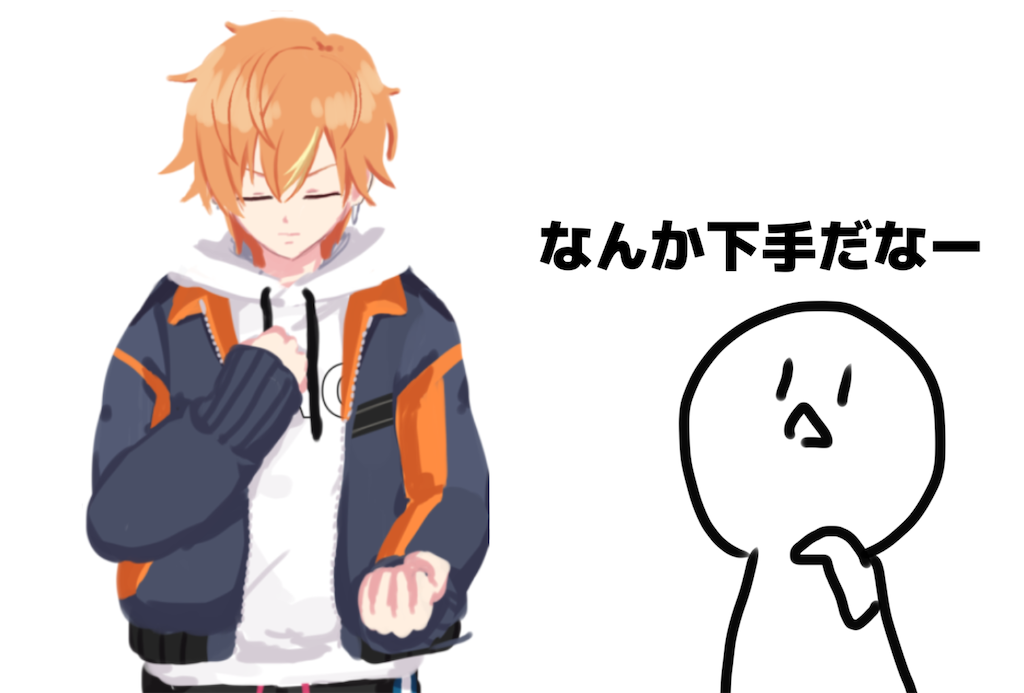
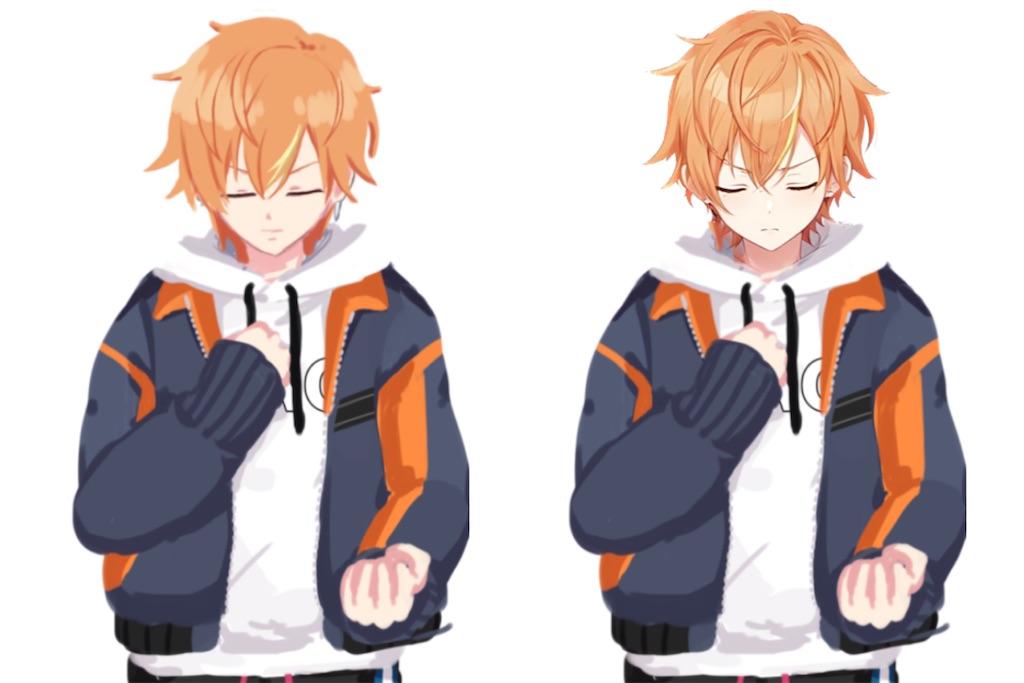
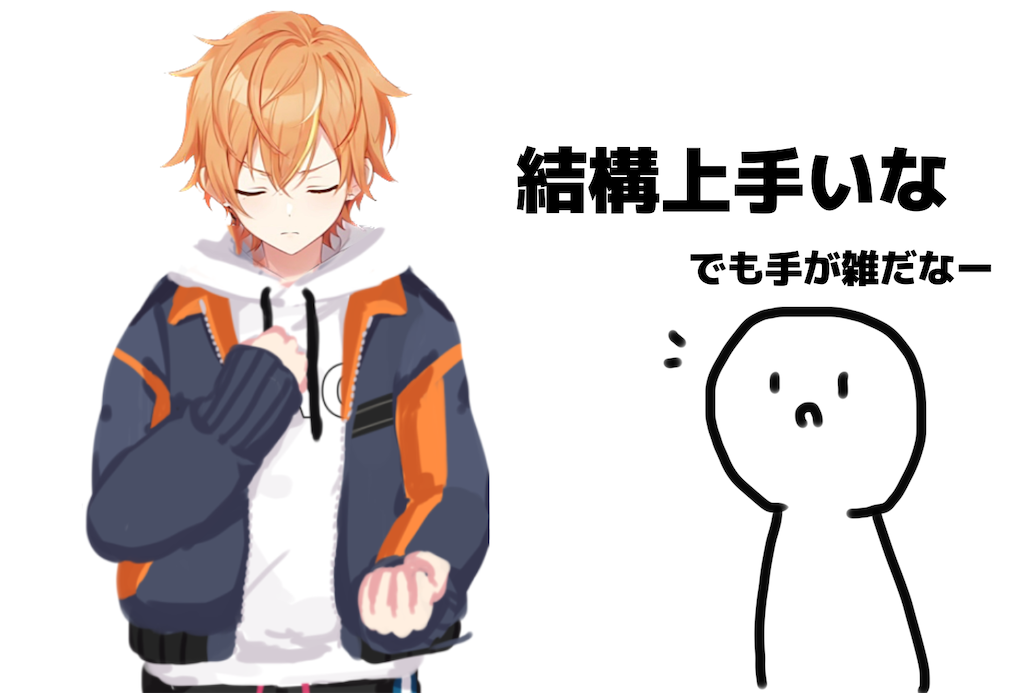
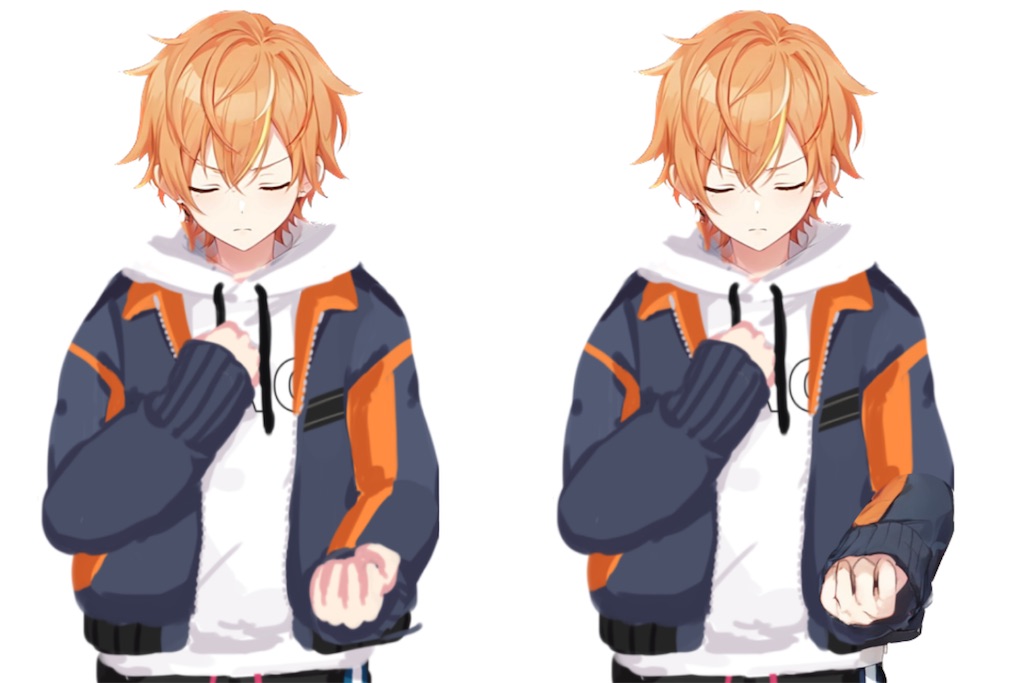
今回は、動画に寄せられた様々なコメントのなかで、画像生成AIに批判的な意見について、幼少期から絵を描き続けた1人として、考えを述べさせてもらおうと思います。
「AIに負けた」と感じる人々
これがAIって
もう負けたなぁ…
AIの時代か……
AI進化しすぎでしょ。もう勝ち目ないじゃん
人間vsAIと考える人が非常に多いとコメントを見ていて思います。
不安や嫌悪感はわかります。
どれだけ絵の勉強をして、画力が上がっても、AIが簡単に追い越してしまう。AIはプロンプトを入力するだけで、簡単に魅力的な絵を描いてしまう。
「自分が絵を描いてきた意味は?」
「努力の意味は?」
すべて無駄だったの?
私の絵はいらないの?
そんな風に思う気持ちは、痛いほどよくわかります。
初心者の絵は昔から価値が無い
強烈最強画力神様大量生産無料最速神絵師なんてものが生まれたら、私のような永久お絵描き初心者が描いた絵に、価値なんて無いですよ。
永久お絵描き初心者の私の絵なんて
めずらしい!人間の絵だ!!人間が描いているなんて貴重だね!
程度の価値でしょう。「人間が描いた絵」というのが珍しいから見てもらえるだけです。
そして、その後に
でも、下手くそw
こんなにダメなもの上げて恥ずかしくないのかな?描かなきゃいいのにwww
と笑われるのです。展開は見えています。
でも、これは今に始まったことではないのです。AIによって引き起こされる評価ではありません。
お絵描き初心者の絵に価値がないのは、何年も昔からです。
検索のジャマだから消して
この言葉は、 AI登場前に私が言われた 本当のコメントなのです。
いつだって求められているのは神絵師だけであり、他の絵師はゴミで目障りで邪魔で消えてほしい存在と思われているのです。
これまでの神絵師も価値が無くなる?
強烈最強画力神様大量生産無料最速神絵師画像生成AIなんてものが生まれたので、必然的に神絵師と呼ばれる基準は上がったでしょう。
twitterやpixivなどによって神絵師と比較される機会が増え、初心者が相手にもされなくなったのと状況は同じです。
画像生成AIという神絵師と比較されるようになり、今までの神絵師が「AIに勝る天上の神絵師」「AI以下の神絵師」に分かれたのです。
「AI以下の神絵師」は、いずれ普通絵師か初心者扱いとなり、
検索のジャマだから消して
と言われるようになるかもしれません。悲しいですが、避けようがなく仕方の無いことだと思います。
将来求められるのは、AIにも勝る神絵師だけであり、AI以下の絵師は、現在の初心者絵師同様に、ゴミで目障りで邪魔で消えてほしい存在と思われるかもしれません。
AI時代に絵師は不要なのか?
AI時代も 絵師は必要であると考えています。
ですが、AIに描ける絵だけを描く絵師は、不要になると思います。
具体的に、どのような絵師がまだしばらく必要になるかと言うと、
神絵師、ニッチな絵を描く絵師、AIを活用する絵師は、AI時代も長い間必要になると思います。
生き残る絵師とは
①神絵師が必要になるのは、AIが勝てない神だからです。圧倒的強者は今後も必要です。
②ニッチな絵を描く絵師が必要になる理由は非常に簡単で、
- 学習モデルを作れるほどのサンプル数がない
- そもそもニッチすぎて学習モデルを作る人物がいない
供給が少ないジャンルはどう足掻いても、AIでは補えないんですよね。
様々な人が描いて、それからはじめて、学習モデルができるのです。
なので、今後もしばらくこの手の絵師は必要になると思います。
③AIを活用する絵師は、必要になるというよりも、自然に増えると思います。
画像生成AIによって、綺麗なイラストが簡単に描けるようになり、今まで絵を諦めていたような永久お絵描き初心者の私のような人間が、また絵を描き始めたりもするでしょう。
過去に培った画力は無駄にはならず、AI画像をトレスしたり、修正したり、様々な場面に使われることになります。
実際の使用例はコチラ↓
私は修正にまだ5~20時間かかるので、もっともっと画力向上に努める必要があります(´ω`)トホホ…
まとめ
「AIに負けた」と感じる人々が増えている。
AIはライバルだが、良き道具。
神絵師に囲まれて、ゴミカス扱いされていた初心者絵師は、今がチャンス!!!
新しい道具と今ある画力を活かして、もう一度絵を描いてみるべき( •̀ᄇ• ́)ﻭ✧
そしてまた絵を練習すると、なおよし!
 あれ?もしかして
あれ?もしかして